内存泄露在实际开发过程中会比较经常遇到,如何排查和解决是非常关键的。“工欲善其事必先利其器”,找到好的工具才能事半功倍。本文将介绍使用
IDEA Profiler排查问题。
背景
最近通过Pinpoint的监控发现有个服务堆内存一直高居不下,不时触发Full GC,徘徊在危险的边缘。虽然从监控上看频率还不会太高,每次停顿时间相对也比较短,还是担心有一定隐患,因此需要针对性的做一些排查。
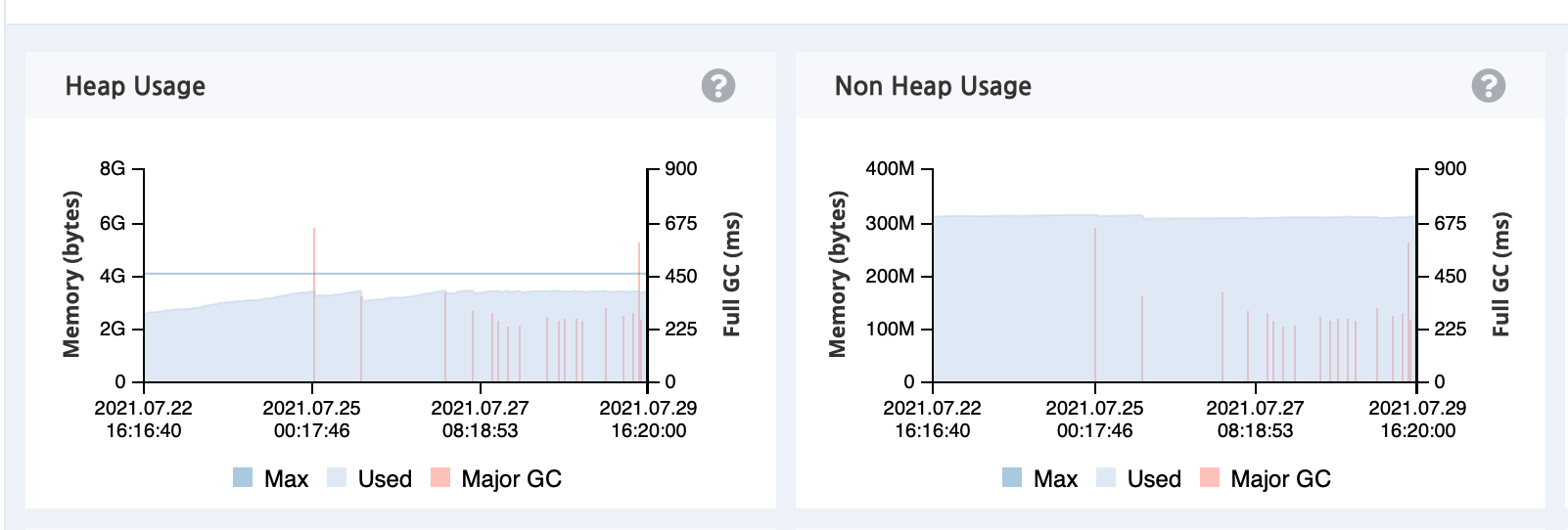
排查
排查还是需要一些产线的环境和数据做支撑,因此决定找其中一个服务节点,将堆和栈信息导到本地进行分析。于是联系运维执行以下命令:
# 导出线程信息
jcmd <PID> Thread.print > thread.tdump
# 堆转储
jcmd <PID> GC.heap_dump heap_dump.hprof
# 类信息
jcmd <PID> GC.class_histogram > class_histogram.txt备注:由于思考不周,堆转储的时候触发了STW,因此在短时间内对业务带来了一定的影响,也是前期考虑不周的地方。
分析
分析线程信息
从线程信息上看没有BLOCK、Deadlock等的相关信息,整体情况正常。
分析类信息
发现java.util.HashMap$Node有19949698个实例,占用内存将近900M。猜测这边有问题,但是还没法定位。
分析堆转储信息
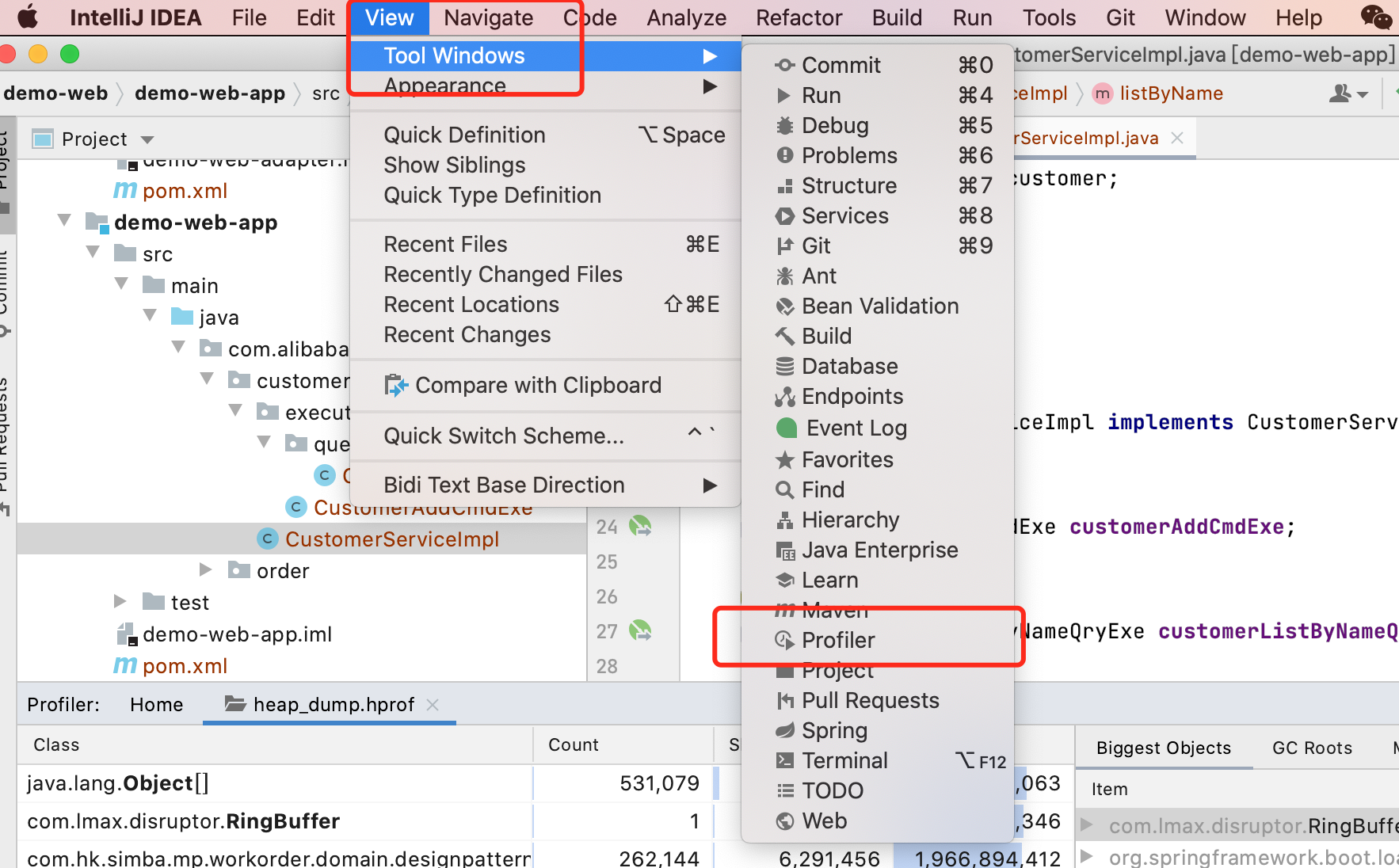
通过IDEA的Profiler进行堆分析,步骤如下:
- 打开Profiler窗口,路径为:View → Tool Windows → Profiler
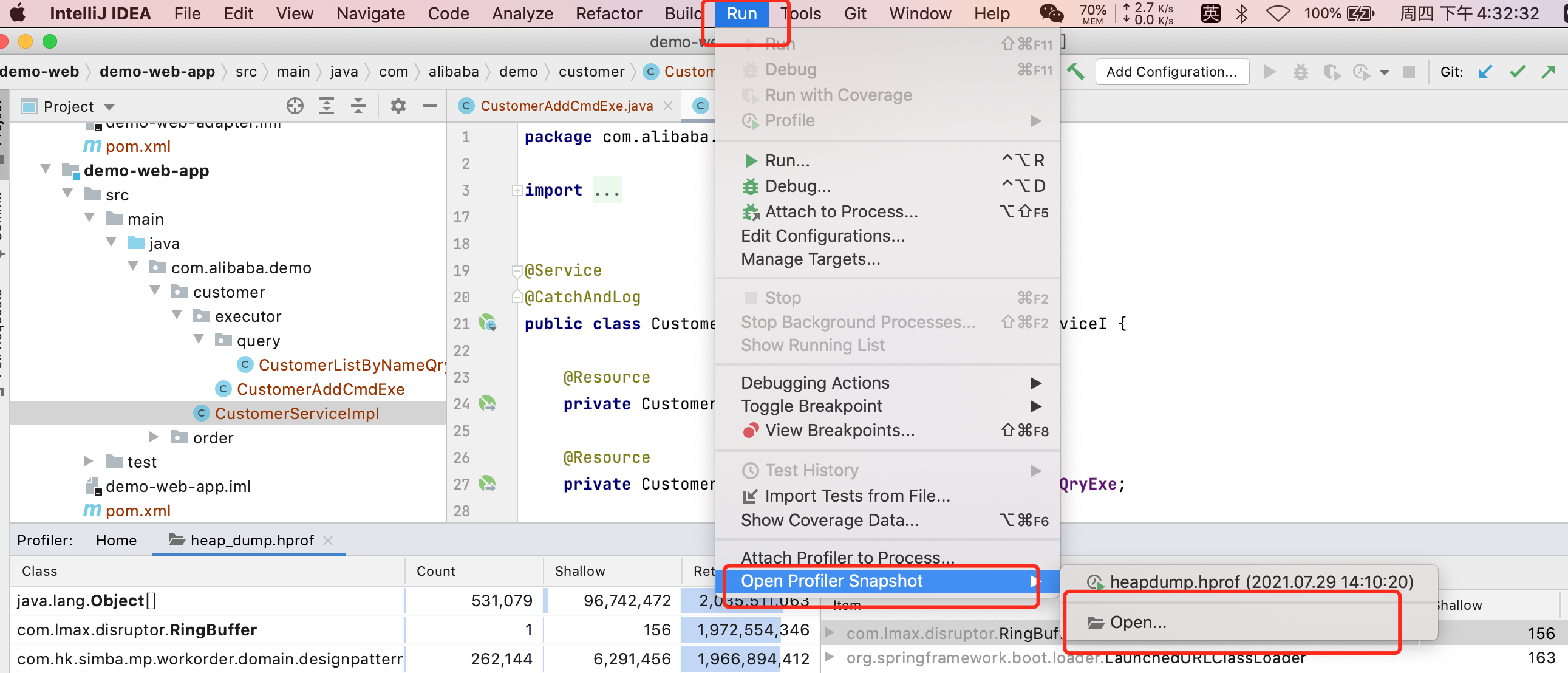
- 打开堆转储信息,路径为:Run → Open Profiler Snapshot,然后选中dump的信息
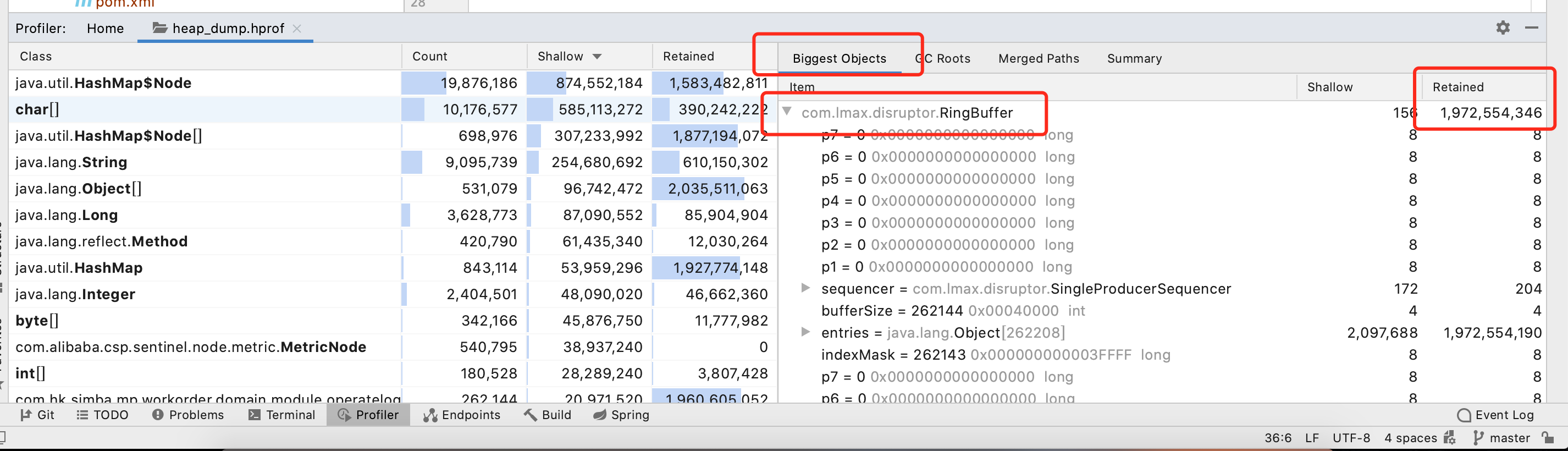
- 等待解析完成,此时可以通过窗口看到整体的情况,还是可以发现
java.util.HashMap$Node的内存占用较大。切换到Biggest Objects可以看到RingBuffer的Retained占1.9G多,怀疑跟Disruptor框架有关系。
因此看了下这块的初始化配置,发现环形大小设置为1024x256,也就是26万个环形大小,按目前的业务情况每个对象占用8K左右,就是将近2G的堆空间了,符合现状。初始化代码如下:
@Configuration
@Slf4j
public class DisruptorConfig {
@Bean("logEventRingBuffer")
public RingBuffer<CreateLogEvent> messageModelRingBuffer(final CreateLogEventHandler createLogEventHandler) {
//定义用于事件处理的线程工厂
ThreadFactory threadFactory = Executors.defaultThreadFactory();
//指定事件工厂
CreateLogEventFactory factory = new CreateLogEventFactory();
//指定ringbuffer字节大小,必须为2的N次方(能将求模运算转为位运算提高效率),否则将影响效率
int bufferSize = 1024 * 256;
//单线程模式,获取额外的性能
Disruptor<CreateLogEvent> disruptor = new Disruptor<>(factory, bufferSize, threadFactory, ProducerType.SINGLE, new BlockingWaitStrategy());
//设置事件业务处理器---消费者
disruptor.handleEventsWith(createLogEventHandler);
// 启动disruptor线程
disruptor.start();
log.info("disruptor started");
//获取ringbuffer环,用于接取生产者生产的事件
RingBuffer<CreateLogEvent> ringBuffer = disruptor.getRingBuffer();
return ringBuffer;
}
}按照目前的情况,只需要将这个值调小,例如1024x8即可,这样可以最大限度减少占用的堆空间。
备注:Profiler上看到的Shallow和Retained代表的意思如下:
Shallow:对象本身占据的内存的大小;
Retained:当前对象大小+当前对象可直接或间接引用到的对象的大小总和。
关于Shallow Size和Retained Size的区别详见:https://blog.csdn.net/a740169405/article/details/53610689。
总结
- 用框架之前要对具体的配置有更清晰的了解,避免出现状况的时候束手无策,也容易产生问题;
- 后面需要考虑更好的方式来对产线的堆做转储,避免STW的产生。目前还未有好的方案,欢迎有想法的朋友交流。

