故障现象
下午运维群推送了一个K8S告警,某个服务CPU飙高,如下:
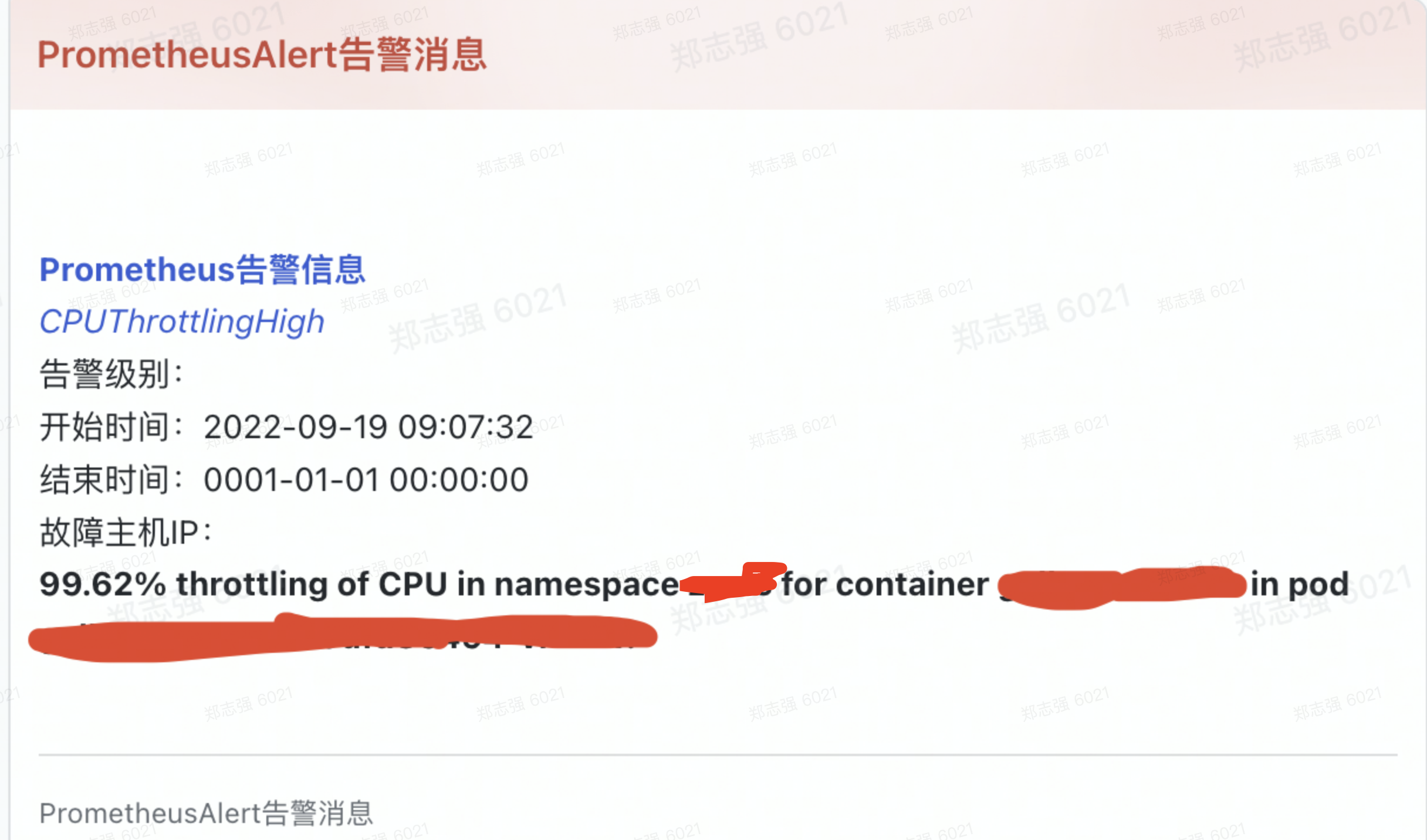
由于已经达到申请资源的临界值了,因此需要尽快对服务进行排查。
故障排查
基于k8s dashboard登录Pod,打印jstack日志:
# 打印jstack日志
jstack 1 > jstack.log
# 基于线程状态进行分组统计
grep 'java.lang.Thread.State' jstack.log |awk '{print $2$3$4$5}'|sort -n|uniq -c统计线程状态后如下:

看着线程数不多。
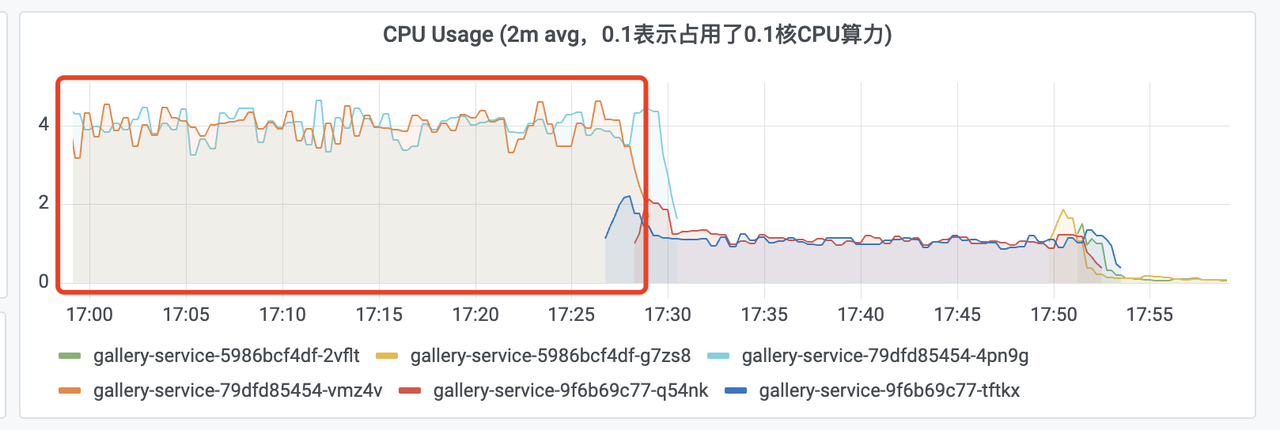
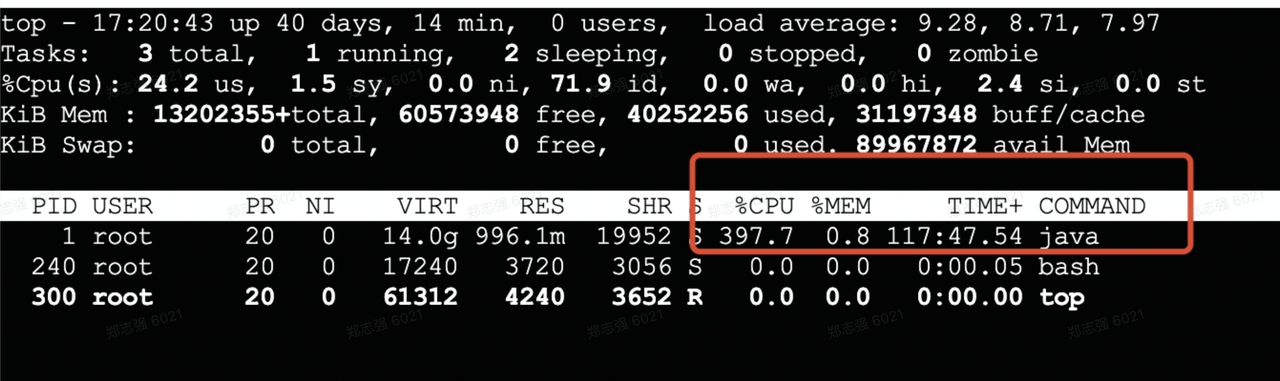
接下来查看top发现是Java进程导致的,如下图:
继续看是Java里面哪个线程使用导致的,如下:
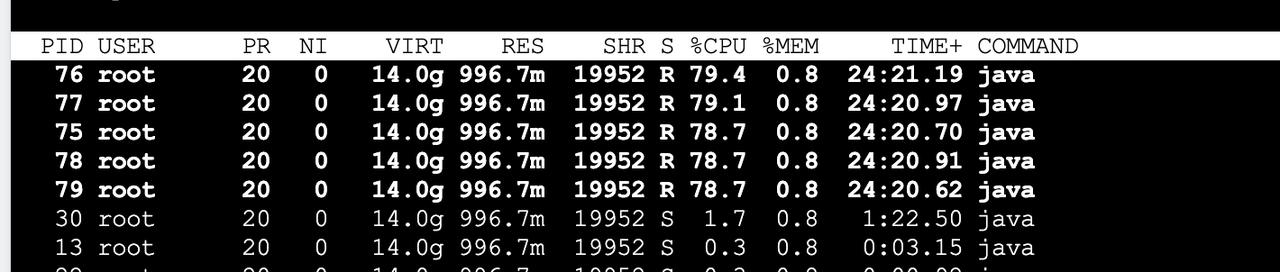
发现是75、76、77、78、795个线程的使用率都在80%左右,而且一直持续。接下来针对线程id进行转换(10进制转16进制),如下:
# 线程id由十进制转十六进制
[root@service-9f6b69c77-q54nk /]# printf "%x\n" 75
4b
# 搜索jstack日志查看是哪个线程
[root@service-9f6b69c77-q54nk /]# grep '0x4b' jstack.log
"consume-database-sync-task-0" #66 daemon prio=5 os_prio=0 tid=0x00007f9b0289a800 nid=0x4b runnable [0x00007f9a6161c000]发现是线程consume-database-sync-task-0导致,跟开发确认,这个地方的设计存在问题,一直在进行while循环拉取数据导致。代码大致如下:
while(true) {
// 查询数据
// 处理数据
}后让开发调整编码方式解决。

