背景
在开发、测试甚至产线环境,我们经常会遇到这样那样的难题,例如接口响应慢、服务器CPU飙高、Java应用内存居高不下等问题。遇到这类问题,应该如何来排查分析?本文将主要从JVM tool以及Arthas等几个方面跟大家分享,如何快速分析并解决问题。
排查思路
日志分析
相信每个开发同学,在遇到问题的时候都会去搜索日志。
- 科学打印日志
- 避免打印无效日志
- 做好异常归类,业务异常和错误要区分开(重要)
一般来说业务异常是符合预期的,而错误本身是预期外的,绝大多数情况下我们更多会关注错误本身。做好异常的归类也有助于后续的告警和推送,例如基于logstash的output插件我们可以实现错误信息推送到飞书群聊(前提是归类好,否则业务异常如果也推送的话会造成干扰,真正的错误信息被淹没)。 - 异常的时候打印完整堆栈
常规的一些HTTP服务一般会通过GlobalExceptionHandler做拦截打印,对于Job或者MQ Consumer之类的,需要做好try…catch及堆栈的打印;或者出现异常的时候进行了catch,但是没有记录异常信息,例如:logger.error(“xxxx”),而不是logger.error(“xxxx”, e)
- 快速查找
- 统一的日志规范,有助于统一的采集和入库
- 统一的TraceID,便于分布式系统排查
- 熟练掌握ELK进行搜索(例如界面搜索、写KQL等)、熟练掌握linux命令进行文件搜索(例如more、grep等)。
另外,在使用一些三方框架的时候,对于一些出现概率比较多的问题,可以多总结和复盘,后续出现的时候可以根据关键字快速筛选出问题。例如原来在使用Dubbo的时候,偶尔会出现线程池满(默认200)的问题,日志中会出现以下信息:
Caused by: java.util.concurrent.RejectedExecutionException: Thread pool is EXHAUSTED!
那么后续在应用出现问题的时候会根据经验搜索关键字EXHAUSTED,确认是否跟线程池有关系。
APM
APM的原理大同小异,都使用了Java-Agent的方式来实现。 Java-Agent是一种能够在不影响正常编译的情况下,修改字节码。
APM除了实现链路追踪,还可以实现告警(设定告警规则、webhook等)。通过告警机制可以在系统出问题的时候及时推送告警,这时候开发人员可以登录APM查看对应时间段系统的各项监控指标以及链路信息,能很好的追溯和排查。
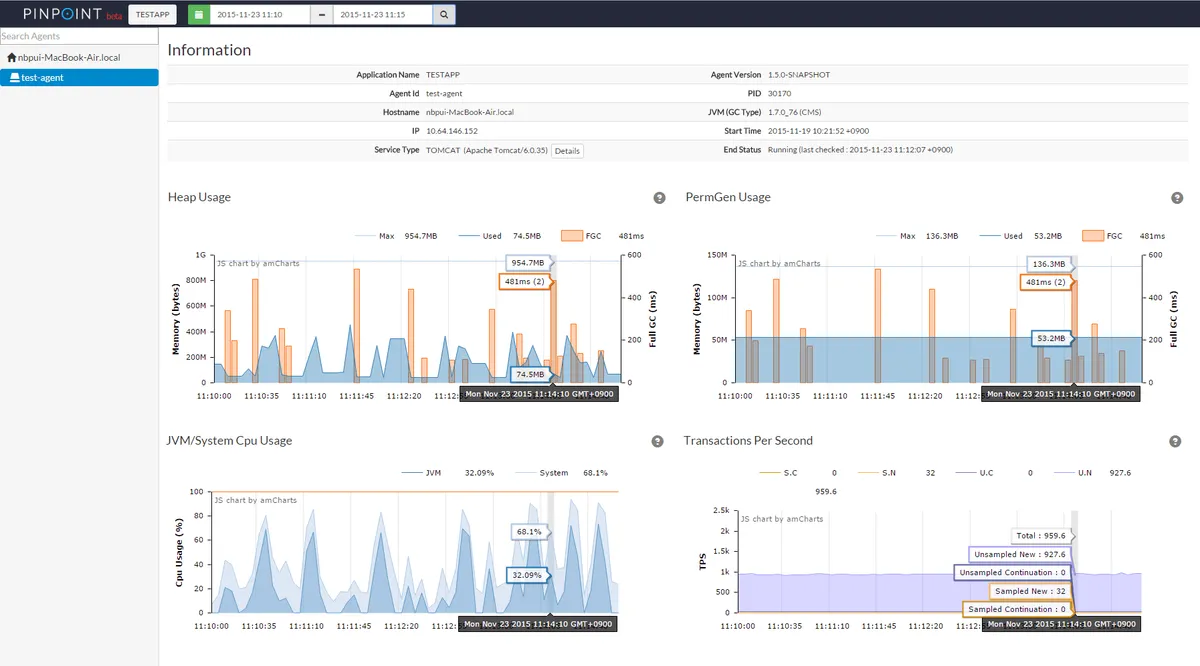
Pinpoint
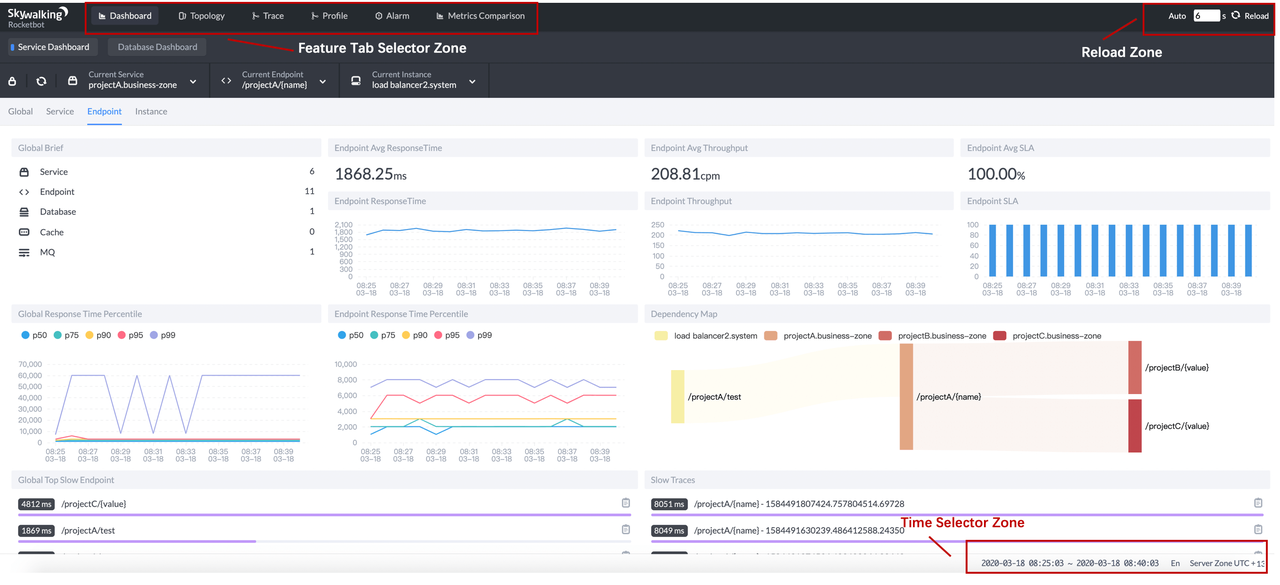
Skywalking
JVM Tool
JVM Tool是JDK自带的工具,常见的有jps、jstack、jmap、jcmd等。其中jcmd集成了前几者的功能,也是官方推荐使用的工具。下面简单介绍几种常规的排查方式。
栈分析
通过以下方式可以dump线程信息:
# 方式一:通过jcmd打印
jcmd <PID> Thread.print > thread.tdump
# 方式二:通过jstack打印
jstack <PID> > thread.tdump打印之后可以通过以下命令统计分析线程信息:
grep 'java.lang.Thread.State' jstack.log |awk '{print $2$3$4$5}'|sort -n|uniq -c将top -Hp里面的线程id转为jstack日志中的id(对应nid),如下:
# 将十进制转为16进制
printf "%x\n" 22414以下基于压测过程中的jstack进行的分析,如下:
[root@87d77c3444ec jstack]# grep 'java.lang.Thread.State' jstack.log |awk '{print $2$3$4$5}'|sort -n|uniq -c
7 BLOCKED(onobjectmonitor)
68 RUNNABLE
2 TIMED_WAITING(onobjectmonitor)
22 TIMED_WAITING(parking)
5 TIMED_WAITING(sleeping)
3 WAITING(onobjectmonitor)
195 WAITING(parking)
// 以下为压测结束打印jstack的情况
[root@87d77c3444ec jstack]# grep 'java.lang.Thread.State' jstack.log.idle |awk '{print $2$3$4$5}'|sort -n|uniq -c
25 RUNNABLE
2 TIMED_WAITING(onobjectmonitor)
67 TIMED_WAITING(parking)
4 TIMED_WAITING(sleeping)
3 WAITING(onobjectmonitor)
196 WAITING(parking)当然,针对jstack还有一些诀窍,一般搜索DEAD、BLOCK等关键字,另外就是查看公司自己的package是否有出现,如果有可以先优先分析对应的代码。
堆分析
堆一般都有几个G,转储的时候会触发STW,因此在转储的时候要确保从微服务中摘除,确保没有流量之后再执行。
jcmd <PID> GC.heap_dump heap_dump.hprof转储之后可以通过IDEA自带的JProfiler(下面案例会介绍)或者Memory Analyzer (MAT)进行分析。对于有内存泄露嫌疑的,通过分析可以比较快分析定位到问题并解决。
其他命令
# 列出所有的java进程
jps -l
# 类信息
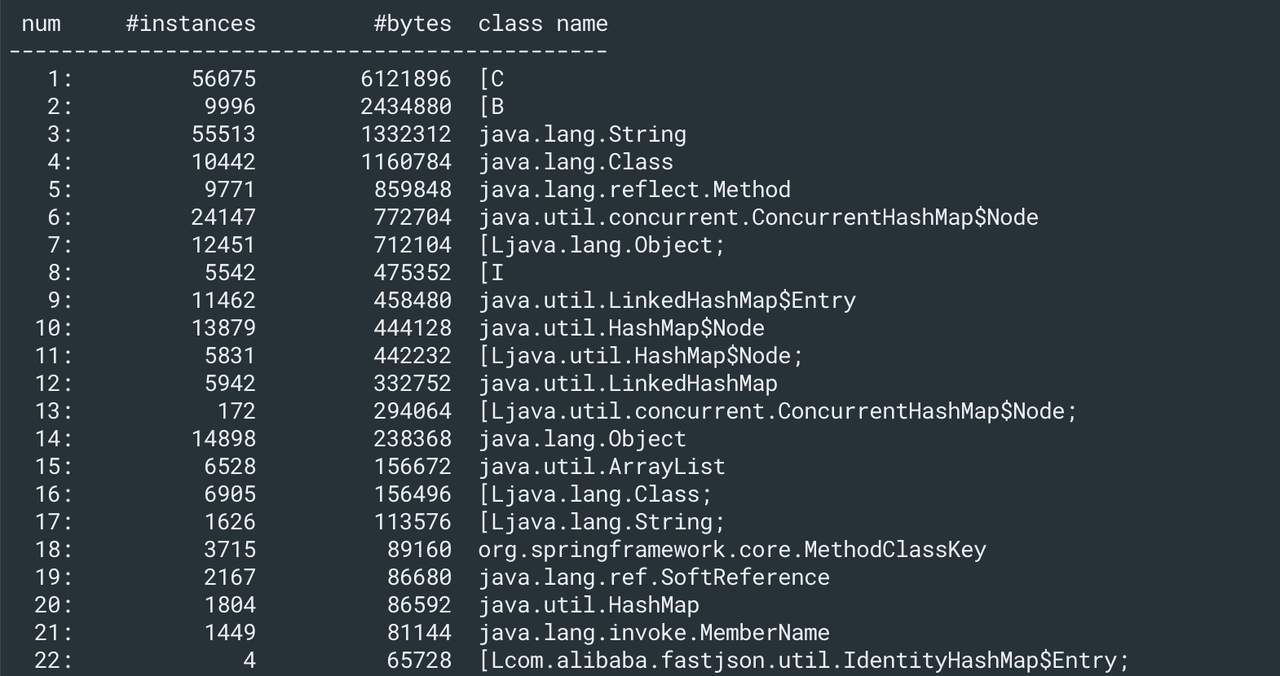
jcmd <PID> GC.class_histogram > class_histogram.txt
# 查看存活的实例信息,可以查看对应的实例是否有初始化
jmap -histo:live <PID> | grep XXXclass_histogram.txt内容信息:
Arthas
Arthas是Alibaba开源的Java诊断工具,深受开发者喜爱。在线排查问题,无需重启;动态跟踪Java代码;实时监控JVM状态。
Arthas 支持JDK 6+,支持Linux/Mac/Windows,采用命令行交互模式,同时提供丰富的 Tab 自动补全功能,进一步方便进行问题的定位和诊断。
介绍比较常用的几个命令:
# 查看实例对应的属性信息,展开N级
vmtool --action getInstances --className org.springframework.cloud.netflix.zuul.filters.route.SimpleHostRoutingFilter -x 2
# 调用方法修改数据
vmtool --action getInstances --className org.apache.http.impl.conn.CPool --express 'instances[0].setDefaultMaxPerRoute(1000)'
# 通过仪表盘查看信息,命令详情:https://arthas.aliyun.com/doc/dashboard.html
dashboard
# 查看最忙的线程信息 https://arthas.aliyun.com/doc/thread.html
thread -n 10总结
每个技术团队都会出现这样那样的技术问题,问题本身并不可怕,可怕的是被打倒或者花了很长时间才解决它。
因此,一方面平时要做好相关的储备,对于使用的技术框架深入去了解细节,团队内要有人能够驾驭;另一方面,我们要变被动为主动,要建立完善的监控和告警机制,比用户、运营更早发现问题,这样可以有更多的时间来处理问题,变被动为主动。

